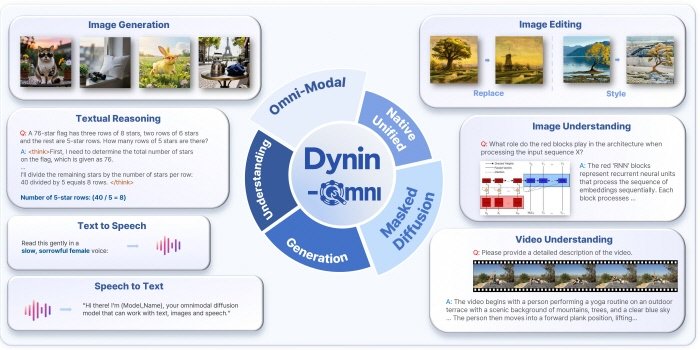
Overview of the next-generation integrated AI foundation model ‘Dynin-Omni’. Provided by Professor Do Jae-young’s team, Department of Electrical and Computer Engineering, College of Engineering, Seoul National University
The research team of Professor Do Jae-young at the Department of Electrical and Computer Engineering, College of Engineering, Seoul National University (AIDAS Lab) announced that it has developed a next-generation artificial intelligence (AI) foundation model, ‘Dynin-Omni’, in which a single model can simultaneously understand and generate text, images, video, and audio.
The team explained that it designed an architecture that enables an AI model to process diverse sensory information at the same time, thereby overcoming the limitations of conventional methods that generate information sequentially. It stated that it has implemented an omnimodal AI that allows a single model to jointly process a wide range of information, from text to video.
Recently, AI has been evolving toward processing various types of data, not only text but also images, speech, and video. However, to interact naturally with humans in real-world environments, AI must go beyond simple recognition and demonstrate complex processing capabilities. For example, functions such as recognizing speech to generate images, or analyzing video and explaining it through audio, require an integrated processing architecture that simultaneously exploits multiple sensory inputs.
Conventional AI systems typically separate understanding and generation functions or combine multiple models, which has limited their ability to process different forms of information in an organic manner. In particular, building an integrated architecture in which a single model simultaneously processes diverse sensory information and generates outputs has been regarded as a technically challenging task.
To address these limitations, the research team designed an architecture in which a single model processes information in an integrated way and, on this basis, developed the next-generation integrated AI foundation model ‘Dynin-Omni’. This model jointly processes text, image, video, and audio data and features an architecture in which both understanding and generation take place within a single model.
A key characteristic of Dynin-Omni is its architecture that integrates and processes various forms of information according to a single standard. Whereas existing AI systems typically convert image or audio information into text-centric representations, this model is designed to process multiple types of data in the same manner.
In addition, it adopts a diffusion method that generates the entire output at once and then refines it, in an effort to improve processing efficiency. Compared with the conventional approach of generating words sequentially, this is described as an architecture better suited to handling large-scale data.
Furthermore, by integrating understanding and generation functions into a single model, it proposes a structure different from the existing approach of combining multiple models. The team stated that, through this, it sought to implement a method that links and processes various sensory information in a unified way.
According to the research team, Dynin-Omni demonstrated improved performance over existing integrated models in a total of 19 global AI performance benchmarks across diverse domains, including information reasoning, video understanding, image generation and editing, and audio processing. It also reported that improvements were observed in generation speed compared with existing integrated AI models.
ⓒ dongA.com. All rights reserved. Reproduction, redistribution, or use for AI training prohibited.
Popular News