※ Seoul National University of Science and Technology supports early-stage startups in the deep tech (AI and big data) sector. Based on the university’s customized growth support program, ITDongA examines promising deep tech startups that are achieving clear results in the market.
“We want to define the standard for hearing intelligence.”
Social concerns about care and safety are gradually increasing. There is a growing need for technologies that can detect moments such as when an elderly person living alone collapses, a child is crying, or someone is calling for help in an alleyway. In particular, as non-face-to-face medical treatment and remote care services spread, attempts are being made across various fields to use technology to compensate for situations where people cannot directly see or hear.
CEO Kim Seong-eun of Medisensing / Source=ITDongA
Startup Medisensing is responding to this social demand. In particular, it is taking on challenges from the medical field to everyday safety and care, using artificial intelligence (AI) technology that listens to sounds and interprets their meaning and context. Beyond simple speech recognition, it is also developing advanced AI technologies that understand non-verbal sounds such as screams, crying, and calls for help, and that can assess situations. ITDongA interviewed Medisensing CEO Kim Seong-eun about the company’s motivation, strategy, and vision.
Decision to start a business while researching AIFounded in 2024, Medisensing combines “Medical” and “Sensing.” CEO Kim explained, “Medisensing was established to create technology that can make a tangible contribution to society by detecting signals generated by the human body and in daily life, and understanding their meaning.”
Kim is also a professor in the Department of Artificial Intelligence at Seoul National University of Science and Technology and a researcher who, over the past five years, has published more than 12 papers in top 10% international journals in the AI field focused on understanding biosignals, brain waves, and sound signals. While conducting research in AI, Kim decided to start a business to ensure that the technology would go beyond academic papers and contribute to society.
CEO Kim decided to start a business while researching AI as a professor in the Department of Artificial Intelligence at Seoul National University of Science and Technology / Source=ITDongA
Kim recalled, “Through joint research with hospitals, we applied AI technology and found that it could distinguish abnormal breathing sounds with higher-than-expected accuracy. At that time, beyond the technological achievement itself, it became clear that ‘this technology could actually help someone.’ In particular, I thought that if this technology could be implemented using only a smartphone microphone, it could provide basic auscultation assistance even in environments with low medical accessibility.” Kim continued, “Through this experience, I came to believe that it is important not to let research results remain at the paper level but to realize them as tangible value. That decision led to the founding of the company,” adding, “I also wanted students to directly experience the entire process of technology being materialized into actual products and services beyond the laboratory.”
Expanding into a sound sensing AI platform that integrates key soundsMedisensing’s core technology is AI that can accurately recognize meaningful individual sounds and understand the situation, even within complex real-world noise environments. The company is developing SSI (Sound State Intelligence) technology, which analyzes sound data to assess states and induce actions. General-purpose models excel at classification tasks such as labeling sounds as “this is crying” based on learned criteria, but they inherently generate many errors. SSI, in contrast, uses each household’s usual sound environment as a reference and simultaneously evaluates “how significant a deviation this sound represents compared with usual.” By combining time-series patterns with LLM-based contextual reasoning, it essentially answers the “why” and “what” behind the sound. For example, it interprets a child’s sustained high-pitched crying not as simple crying, but as a potential sign of pain or abnormal symptoms.
Kim said, “When a baby’s crying is heard, a general-purpose model typically outputs something like ‘baby cry 0.72’ as a probability. From the user’s perspective, it is difficult to connect that to ‘so what exactly should I do now.’ SSI organizes information in a form that users can immediately act on, such as when the crying started, how long it has lasted, its intensity, and whether it has recurred in the last 10 minutes.” Kim continued, “Even for the same baby crying sound, TV volume differs from home to home, and each child’s usual crying patterns vary. SSI first learns the baseline sounds and patterns of that household and that child, and then summarizes deviations from that baseline as events when detected.”
On this basis, Medisensing developed and released in 2025 a beta version of “iMedic,” a self-auscultation tool app for AI-based pediatric respiratory assessment. iMedic’s core function is to measure a child’s breathing sounds using a smartphone microphone, determine whether there are abnormalities, and record and manage the data. It was designed so that anyone could easily operate it at home, with a focus on enabling users to send the recorded sounds to medical staff when needed. However, the company confirmed that additional procedures such as medical device certification are required for the official launch of iMedic, and therefore ended the beta service. Kim said, “iMedic’s core technology is based on research results that have already been published as academic papers,” adding, “Although it did not lead to commercialization, implementing technology that had remained in papers into an actual MVP and validating it in the field was highly meaningful.”
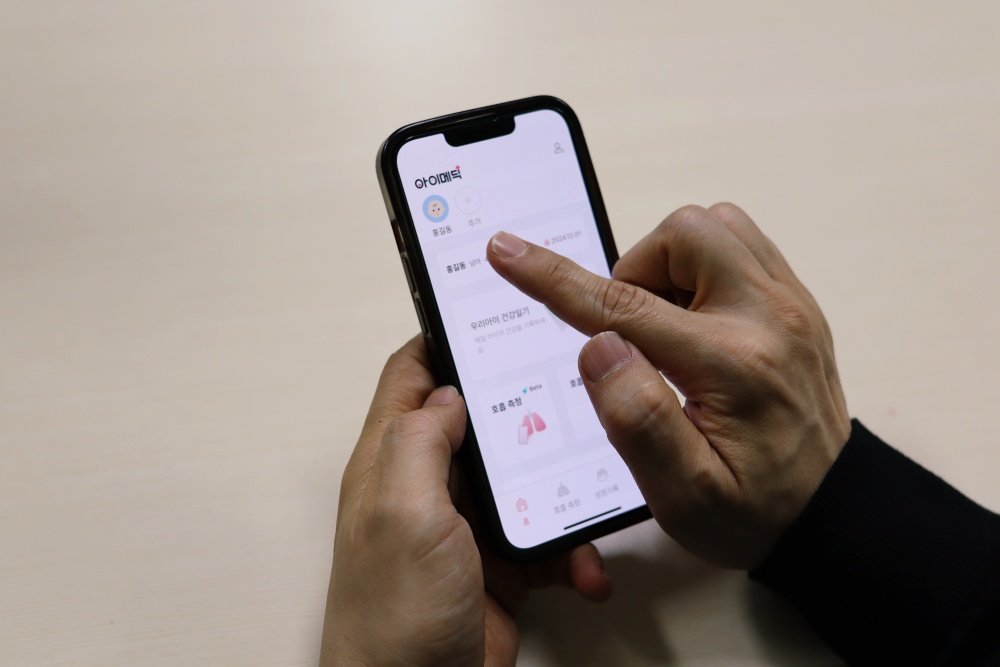
Beta version of iMedic developed by Medisensing / Source=ITDongA
Medisensing is also focusing on developing technology that recognizes five to six key individual sounds such as a child’s crying and screams. Kim said, “We have developed a model that can reliably recognize a child’s crying even in environments where TV sounds, everyday noise, and surrounding conversations are mixed together,” adding, “We are expanding this technology into a sound sensing AI platform that integrates multiple key sounds, rather than limiting it to a specific sound.”
Above all, Medisensing differentiates itself by ensuring its core technology is lightweight enough to operate without large-scale server resources. The company provides this technology in the form of an edge SDK. It plans to enhance utility by designing it so that it can be installed and used on any device equipped with a microphone, such as smartphones.
Accordingly, use cases for the technology are diverse. Representative scenarios include safety systems installed in alleys or public spaces to detect screams or calls for help at night, as well as care-assistance technologies in homes that recognize everything from a child’s crying to whimpering sounds.
Kim said, “What Medisensing aims to create is not just a simple sound recognition function. It is hearing intelligence that supports moments in which humans previously had to listen and judge directly. Although we started with healthcare, we are expanding the technology in a direction that helps safety and care for people in everyday life and across society as a whole.”
Overcoming challenges in data acquisition and real noise environments by changing the approachThe path to developing Medisensing’s technology was not easy. The biggest challenge, by far, was data acquisition. Kim said, “Unlike images or text, publicly available sound data is very limited. In particular, sound data that includes real contextual situations almost does not exist. In the case of medical sounds, in addition to that, clinical validation and ethical considerations are essential, which also imposed practical constraints on development speed.”
Another challenge was that sound recognition technology almost always has to operate “within noise” in real use environments. Kim explained, “Models that work well in laboratory environments often experience a sharp performance decline in real environments where everyday noise such as TV sounds and conversations is mixed. However, it was not easy to sufficiently secure and reproduce such realistic environmental noise.”
The difficulties did not end there. There was also a considerable gap between research and business. Kim said, “Research requires sufficient validation and repetition, whereas business demands rapid execution and pivots. Satisfying these two requirements simultaneously was a continuous challenge during the technology development process.”
Medisensing changed its approach to solve a series of problems / Source=ITDongA
Even so, the company did not give up. To solve the problems, it changed its approach from the ground up. Instead of trying from the outset to comprehensively understand all sounds, it adopted a strategy of defining and recognizing, one by one, sounds whose meaning is clear and that have high social utility. As a result, it has now selected five to six key individual sounds—such as a child’s crying, screams, and calls for help—and is focusing on developing technology that defines and recognizes each of them as an independent unit of meaning.
Kim explained, “After changing our strategy, we were able to clearly delimit the problem scope and rapidly increase technological completeness. To create conditions similar to actual environments, we designed environmental noise in various scenarios and introduced a method of reproducing it by combining it with generative AI. For example, by artificially generating noise conditions assumed for real use environments such as homes, alleys, and indoor public spaces, and using them for training and verification, we were able to develop models that are robust to noise environments. We then lightweighted the models and designed them to operate stably with very low computational resources so they would function properly in real-world environments.”
As a result, through this series of strategies, Medisensing has secured a lightweight sound recognition AI module that does not miss meaningful sounds even in realistic noisy environments. This has become the core foundation of the sound sensing AI platform that the company is currently developing.
At present, Medisensing’s biggest challenge is to precisely identify which “sound-based technologies” the market needs right now. Kim said, “Technologically, we have largely secured AI capabilities that recognize individual sounds and operate reliably in noisy environments. We are now at the stage of clearly defining in what problem contexts this technology becomes a ‘must-have technology.’”
In parallel with technology development, Medisensing is working to validate actual needs through interviews and PoC (proof of concept) projects with various industry stakeholders. It is checking, step by step, which sound recognition functions are most urgently required in the field, in what form they should be provided to have value as a service, and what business models should be built on that basis.
Aiming for phased growth while validating technology and market in parallelMedisensing’s strength lies not in an idea created in a short period, but in research capabilities and outcomes accumulated over many years in the laboratory. Papers in top international journals and a patent portfolio are important assets that are not easy to build at an early startup stage. In addition, the technological capabilities to develop and distribute both cloud APIs and edge SDKs are cited as factors that enhance the company’s potential for collaboration with a wide range of industry partners.
Medisensing participated in the “2025 Early Startup Package Deep Tech Sector Global Open Innovation (Global IR Demo Day) – Next Stage: Global IR for Growth-Stage Startups” / Source=ITDongA
On the basis of this business potential, Medisensing was selected in 2025 for the early startup package program in the deep tech sector by the Startup Support Group at Seoul National University of Science and Technology. Kim said, “Through this program, we received initial funding, which allowed us to secure personnel expenses stably for about five months and create an environment in which we could focus on technology development,” adding, “Beyond funding support, VC meetups, opportunities to prepare and present IR materials, and networking programs were of substantial help. These processes went beyond simple support and helped Medisensing systematically prepare to move on to the next stage.”
Medisensing has also completed an initial small-scale investment contract with the technology holding company of Seoul National University of Science and Technology. The company is preparing to raise seed funding in linkage with TIPS in the first half of 2026. Kim said, “Once stable funding is secured through investment, we plan to expand our core technical staff capable of advancing sound recognition and situation understanding technologies, as well as product planning personnel, and to enhance the completeness of products and services that can be applied in real markets,” emphasizing, “Rather than short-term expansion, Medisensing’s goal is to grow step by step while validating both technology and market.”
According to Medisensing, its mid- to long-term goal is to build diverse sound databases and secure hearing intelligence technology that can simultaneously understand multiple sounds and recognize their situational context. Healthcare was an important starting point, and the strategy is to develop the technology into a core capability that can be expanded to everyday life and across industries.
Medisensing’s vision is “Defining the Standard for Hearing Intelligence.” Kim said, “Humans can roughly grasp situations just by listening to sound, but current AI technology, although excellent in speech recognition, still has limitations in understanding the situational meaning contained in non-verbal sounds,” adding, “Our goal is to create a common standard and structure for which sounds should be interpreted, in what context, and with what meaning.” Kim further noted, “Once this standard is established, it can serve as basic infrastructure for sound-understanding AI in various industries such as robotics, smart homes, autonomous driving, and care services.”
Attention is focusing on what results CEO Kim’s effort to connect long-accumulated research achievements with social value will yield in the market.
Reporter Park Gui-im, ITDongA (luckyim@itdonga.com)
ⓒ dongA.com. All rights reserved. Reproduction, redistribution, or use for AI training prohibited.
Popular News