Over the past decade or so, IT infrastructure has shifted rapidly from on‑premise environments, where servers are physically built and operated, to the cloud. In the early days, secure and well-managed cloud services were often perceived as “nonstop, flawless systems,” but a series of incidents in recent years has shown that the cloud is not a completely faultless framework.
The incident that occurred last year at the National Information Resources Service, which paralyzed the majority of 709 public administrative systems, was something felt by everyone in South Korea. In particular, because all public data had been stored on a single server without a redundancy strategy, the entire national IT infrastructure was brought to a standstill.
The large-scale outage that occurred last October in Amazon Web Services (AWS) East Region (US-East-1) falls into a similar context. An error occurred in the process of connecting DNS, the internet address system, within DynamoDB, AWS’s automatically managed database service, causing disruptions not only for retailers such as McDonald’s and Starbucks but also for financial services including stock exchanges and banks. Ten days later, Microsoft Azure Cloud also experienced outages in retail and airline services due to an employee entering an incorrect configuration value.
On October 17 last year, Kakao Enterprise employees conducted a session at the OpenInfra Summit held in Paris, France / Source = Kakao Enterprise
Through such incidents, awareness has spread that the cloud is no longer an infallible service, and that management measures and operational strategies to prevent downtime must accompany it. Within the industry, strategies are being formulated with a focus on high availability—systems that operate stably over long periods without interruption—and redundancy, which ensures stable use of critical data and systems by distributing them across multiple locations.
Kakao Enterprise’s high availability and redundancy strategyIn the wake of a series of incidents, infrastructure engineers and developers at cloud companies worldwide are seeking technical solutions to enhance server stability and reliability. The OpenInfra Summit held in Paris last October served as a focal point for finding these answers. The OpenInfra Summit is a global open-source conference hosted by the OpenInfra Foundation and was held from October 17 to 19 last year. Key topics included resilience and AI infrastructure, and Kakao Enterprise gave a presentation on IT infrastructure.
Kakao Enterprise Advanced Platform Development Team Manager Yooha Kim (left) and Manager Jihyun Heo (right) / Source = Kakao Enterprise
The presentation by Jihyun Heo, Manager of the Advanced Platform Development Team at Kakao Enterprise, and Manager Yooha Kim was titled “Architecting a Managed Kubernetes Service on OpenStack for Public Cloud Delivery.” It outlined Kakao Enterprise’s strategies for cloud high availability and redundancy.
Manager Heo began the presentation by stating, “This presentation covers how Kakao Enterprise, as a latecomer in the cloud service provider (CSP) market, studied cases from other global CSPs and analyzed how other companies build managed, isolated services. Based on this research, Kakao Enterprise built a fully managed Kubernetes engine with a control plane that is not accessible to users. Currently, clusters are being operated based on multi-AZ (availability zones).”
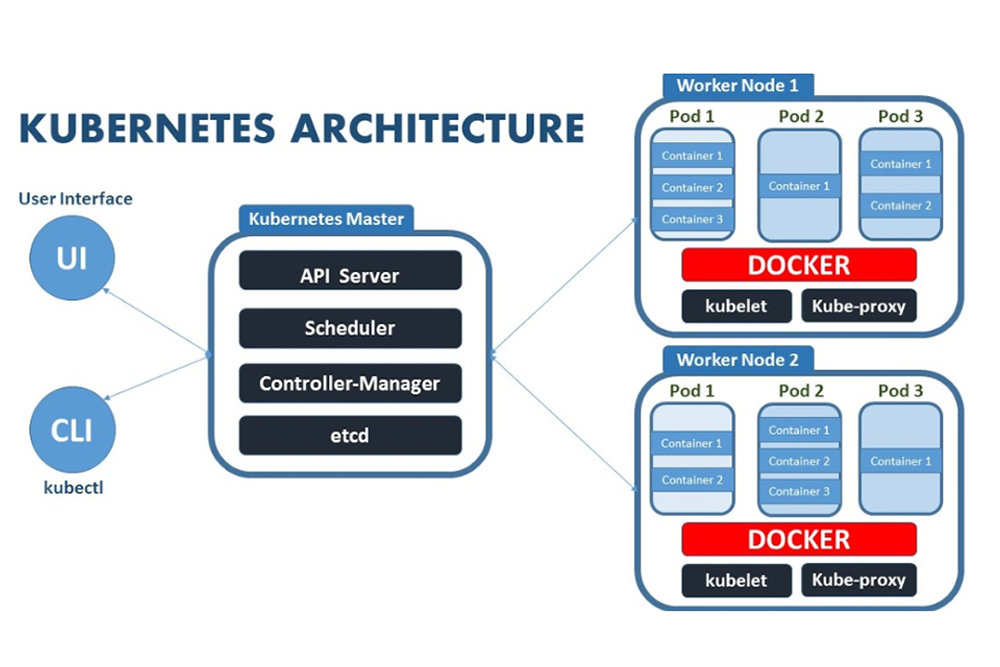
A visualization of the overall Kubernetes architecture. Kakao Enterprise directly manages the ‘control plane’ area, which includes the API Server, Scheduler, Controller Manager, and etcd, to enhance server stability, and physically distributes etcd, which stores state data, to secure resilience / Source = Docker
A “container” is a standardized form that bundles all resources and configurations needed when a developer runs applications and other workloads in the cloud. Hundreds or more of these containers are deployed on the cloud, and the central control system for managing them is “Kubernetes.” Within Kubernetes, there is a “control plane (master node)” area that issues core commands. In consideration of the risk of user error and the difficulty of management, Kakao Enterprise itself is responsible for operating the control plane area.
All resources are containerized so they can be deployed and managed consistently across various environments, and the Kubernetes clusters within the data center and the OpenStack infrastructure are managed as a “ring-zero cluster” layer independently designed by the company. Cluster creation is also standardized using Cluster API.
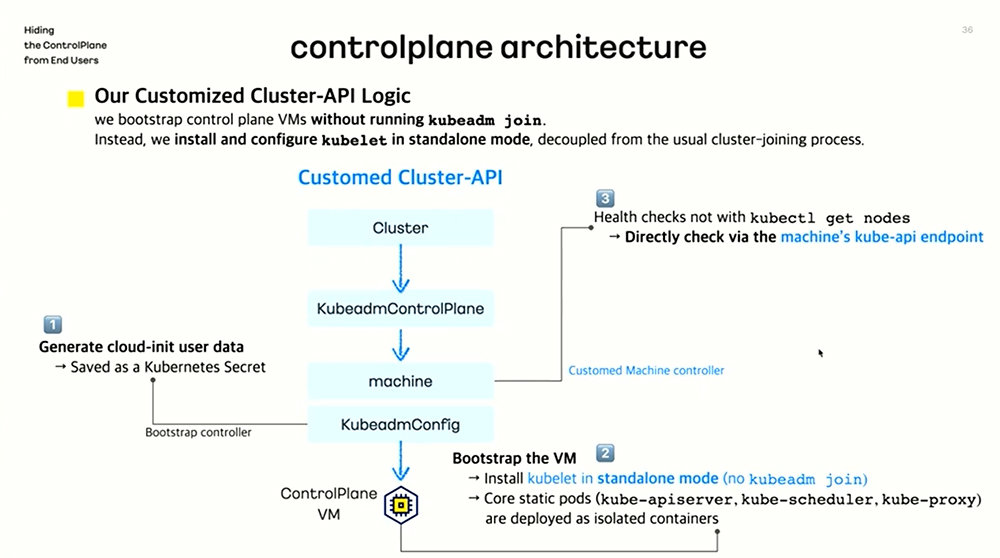
Kakao Enterprise has enhanced server stability by independently improving the Cluster API area / Source = OpenInfra Foundation
For the Cluster API logic, Kakao Enterprise uses its own improved version, and in its Kubernetes engine service it employs an enhanced controller that incorporates automation procedures. In addition, the control plane is configured to run independently from the worker node area, and the elements (static pods) required for cluster operation within the control plane are isolated and hidden at the container level.
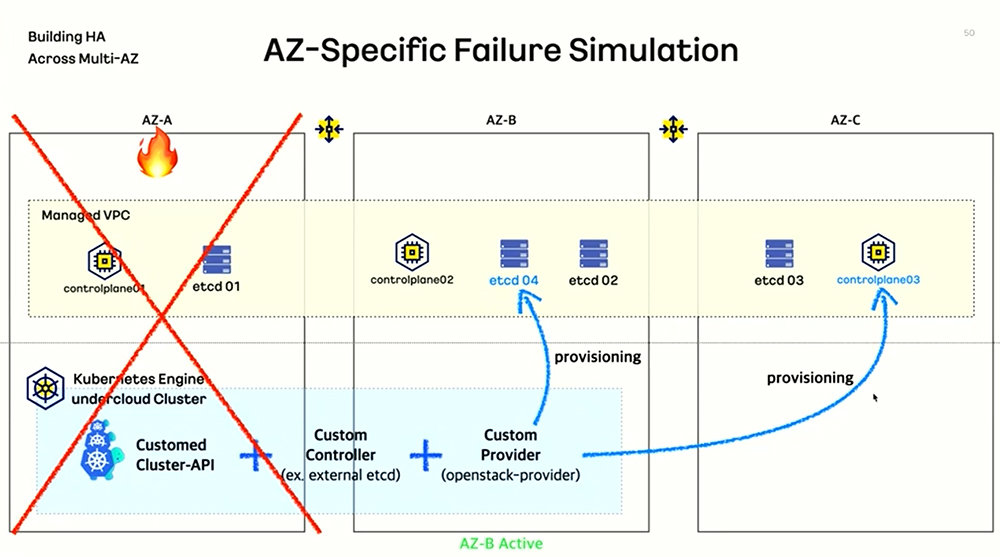
Moreover, etcd, which corresponds to the memory that stores all state information of the data center, is separated from within the node and configured as a separate virtual machine. As a result, even if a loss occurs at the availability zone level, the etcd stored on other servers can be retrieved to ensure service continuity.
By physically distributing etcd, which corresponds to memory including state data, and the control plane machines, Kakao Enterprise has significantly enhanced high availability so that servers can operate continuously / Source = OpenInfra Foundation
Kakao Enterprise uses a “Transit Gateway (TGW)” service that interconnects virtual private clouds and on‑premise networks to implement an ultra-low-latency network communication environment between data centers. Even if one site stops due to a fire or other incident, the control plane and data distributed across other data centers provide service continuity. As data center scale grows, the company can configure the specifications of the control plane and etcd differently or apply Kakao Enterprise’s own specialized network and security settings.
Kakao Enterprise (Kakao Cloud) focuses on ways to operate services as safely as possible even when failures occur / Source = Kakao Enterprise
The key point, according to Manager Heo, is that “One of the important design principles in Kakao Cloud’s Kubernetes engine is to implement multi-AZ by distributing all resources across availability zones (AZ) to secure cloud stability.” Even if a failure occurs in a specific availability zone, data can be immediately fetched from other availability zones that remain active, thereby shortening the time that servers are down.
In summary, Kakao Enterprise’s strategy can be categorized into two main points: ▲ diversifying data centers to ensure that data and services are maintained safely and continuously, and ▲ having Kakao Enterprise, rather than end users, manage the control plane to enable secure service delivery. This approach can significantly reduce losses caused by large-scale outages and also provides clear advantages in terms of high availability by minimizing server downtime.
High availability and stable service as the core of the 2026 cloud industry
The reliability of a data center is defined by the “number of nines.” A server with an availability rate of 99.9% has annual downtime of up to 8.77 hours, while a server with 99.99% availability is allowed only 52.6 minutes. Around 60% of the global data center market is at the 99.98% level, but reality does not always match these figures. It has been proven repeatedly that even global cloud service providers that operate ultra-high-availability servers experience problems due to simple code errors or power outages.
Going forward, cloud providers must prepare for a wide range of potential issues beyond simply meeting visible uptime and operational targets. They are pursuing strategies that prioritize reliability over input costs by increasing automation levels and optimizing architectures. Problems in the cloud are not confined to a single provider; they affect the overall social infrastructure. To build a safer IT era, cloud infrastructure developers are continuously seeking solutions.
IT Donga reporter Nam Si-hyun (sh@itdonga.com)
ⓒ dongA.com. All rights reserved. Reproduction, redistribution, or use for AI training prohibited.
Popular News