Between 2 and 7 December, NeurIPS (Conference on Neural Information Processing Systems) 2025, regarded as the most prestigious academic event in neural networks and artificial intelligence, was held in San Diego, California, USA. NeurIPS began in 1987 as a gathering of biologists, physicists, and computer scientists for research on neural networks and is now considered the world’s largest academic conference on artificial intelligence.
In Google’s academic search system Google Scholar, NeurIPS is recognized as having an impact in the computer science/AI field on par with top-tier scientific journals such as Nature and Science. This year, 21,575 papers were submitted, of which 5,290 (24.52%) were accepted. AlexNet, regarded as the starting point of modern data mining and machine learning; Word2Vec, credited with revolutionizing natural language processing; and the Transformer model, the core technology behind LLMs, were all first introduced at NeurIPS.
The core keywords of this year’s NeurIPS were ▲ step-by-step reasoning capabilities, as exemplified by OpenAI’s o1 model ▲ on-device AI that runs on smartphones and laptops without cloud connectivity ▲ AI safety and alignment related to AI ethics. Among Korean companies, Naver presented 10 papers on topics including efficiency in large-scale AI and robotics, while Viva Republica (TOSS) drew attention with a paper on federated learning optimization.
Kang Ji-hoon, Chief Research Officer of FuriosaAI / Source=FuriosaAI
Meanwhile, AI semiconductor technology company FuriosaAI participated as a “Silver Pavilion” exhibitor, and Chief Research Officer (CRO) Kang Ji-hoon delivered a spotlight presentation titled “Optimizing AI Efficiency from Silicon to Model.”
Kang stated, “The data throughput that a data center can handle is correlated with its power consumption. The reason hyperscalers and AI data center operators seek to invest in power plants ultimately is to increase the processing capacity of their data centers,” adding, “The challenge for the industry is to enable more work to be processed with the same power consumption.”
He continued, “However, if semiconductors are made in a hardwired form (where circuits are implemented as physical wiring at the design stage and cannot be changed), production costs are high and lead times are long. From a performance optimization perspective, a decision ultimately has to be made between using GPUs, which process data batches in parallel, or using dedicated semiconductors specialized for large-scale matrix operations (systolic arrays).”
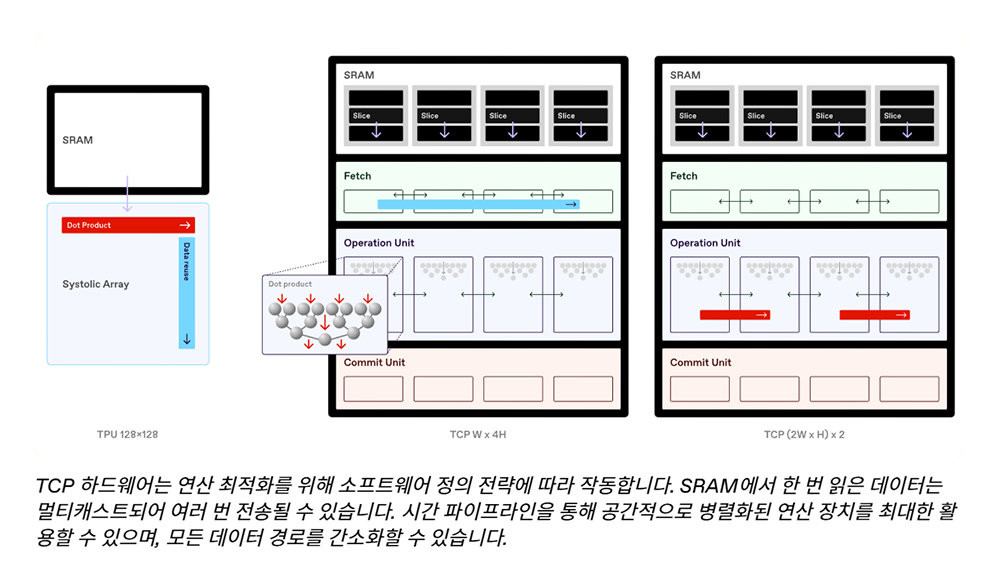
RNGD is a type of semiconductor designed to address the drawbacks of systolic array architectures, where data is processed in a fixed flow / Source=FuriosaAI
GPUs consist of multiple memory hierarchy levels and provide flexible data flow. They are suitable for tasks such as moving data from global memory to local memory. This structure allows free movement of data from external high-bandwidth memory (HBM) to internal memory (SRAM), but requires additional execution time and power consumption. These characteristics make GPUs advantageous for training AI models, but relatively less cost-efficient for inference workloads.
The systolic array architecture refers to products such as Google’s TPU or AWS Trainium, which are designed exclusively for specific tasks. The potential of systolic arrays has recently regained attention with Gemini 3.0 Pro being trained on TPUs, but the data flow in these devices is fixed. While per-operation efficiency is high, the lack of flexible data flow limits their use to specific operations such as matrix multiplication. In addition, because they are designed to meet specific corporate needs, they are typically adopted only in large volumes by particular companies.
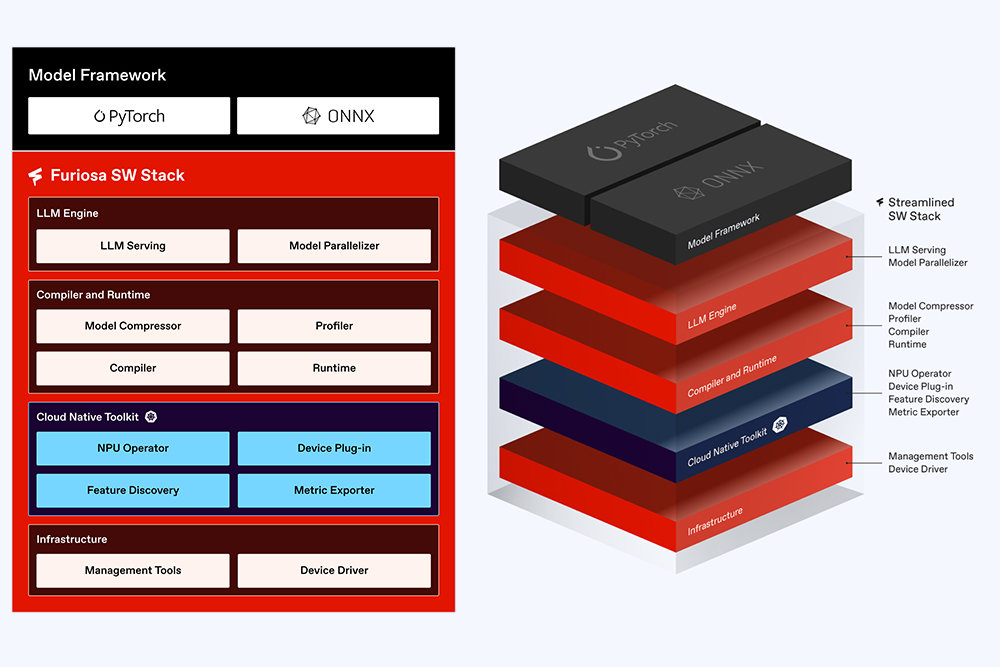
To utilize TCP efficiently, FuriosaAI is steadily building out its software ecosystem / Source=FuriosaAI
FuriosaAI’s RNGD provides a balance between GPUs and systolic arrays through its Tensor Contraction Processor (TCP). Kang explained, “In TCP, SRAM is divided into multiple slices, and the sliced data is routed so that each slice is extracted separately. Data packages are either forwarded as is or distributed across multiple slices.”
In simpler terms, while systolic arrays allow data to flow in only one direction, RNGD can configure the direction of data flow. It manages SRAM in multiple slice units and does more than simply pass data along in sequence: it distributes data across between two and up to eight slices simultaneously. Whereas conventional systolic arrays could only process matrices of predetermined sizes, RNGD splits and processes matrices of any size, enabling hardware resources to be utilized to their fullest extent.
Kang said, “RNGD’s dataflow not only handles data in a fine-grained and efficient manner but is also convenient from a software management standpoint. High-level, intensive operations executed in PyTorch can be directly mapped to the architecture, and results can be easily verified. As a result, FuriosaAI offers an internally built software stack that includes LLM services.”
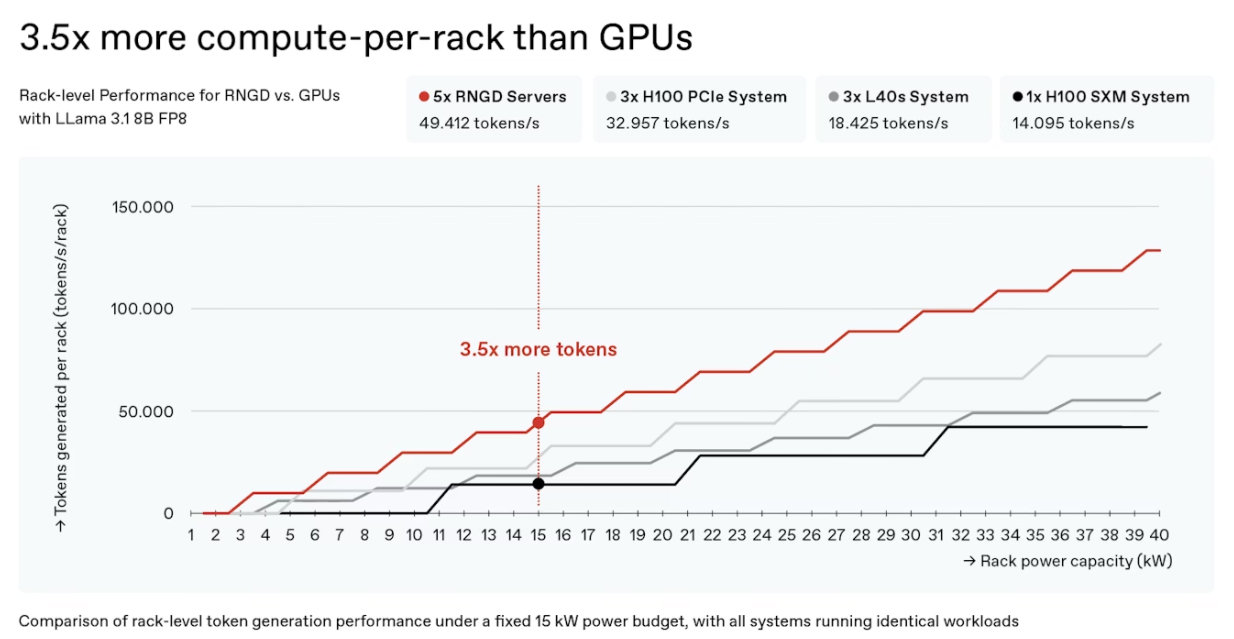
Based on the same 15kW rack, RNGD delivers approximately 3.5 times higher token generation efficiency than NVIDIA’s H100 / Source=FuriosaAI
Following the technical definition of TCP, the company announced that 20,000 RNGD chips will go into mass production starting in January next year and elaborated once more on power efficiency. Kang noted, “The racks currently used in data centers struggle to exceed an average of around 18kW, which is the ceiling for air cooling. With a 15kW rack as the baseline, RNGD can generate 3.5 times more tokens than an NVIDIA H100 system,” adding, “Improving power efficiency also allows higher power density in data centers. The next-generation product will be a 400W-class device, higher than the current 180W thermal design power (TDP).”
Finally, Kang added that “RNGD supports Kubernetes so that it can be managed and deployed efficiently in cloud environments, and it provides low-level access APIs that allow expert developers to build their own optimized compilers and systems.”
‘Sustainable AI computation’ emerges as a key topic in the AI industryAs NeurIPS has grown into the largest academic event in the AI industry, it has also become a venue for various discussions on responsibility related to AI ethics. At the workshop “Tackling Climate Change with Machine Learning,” the focus shifted from the traditional approach of using machine learning to find climate-related solutions to examining the climate-related benefits and costs of building AI models and deriving effective AI approaches for this purpose.
Although many related papers dealt with energy and climate prediction, there were also numerous studies examining existing AI development practices, such as workload distribution to improve data center sustainability and reduce carbon emissions, and LLM-based approaches for large-scale carbon reduction. The conclusion consistently pointed toward the need to use power consumption for AI development more efficiently, which naturally encompasses improving the efficiency of AI semiconductors.
NPU companies such as FuriosaAI are participating in NeurIPS to present such solutions. From January next year, RNGD will enter full-scale mass production and be deployed in AI data centers in Korea and around the world, contributing both to carbon emission reduction and to efficient AI inference. As the topic of “sustainable AI computation” continues to gain prominence, attention to high-efficiency AI semiconductors such as RNGD is also expected to increase.
IT Donga reporter Nam Si-hyun (sh@itdonga.com)
ⓒ dongA.com. All rights reserved. Reproduction, redistribution, or use for AI training prohibited.
Popular News