Today’s large language models (LLMs) are evolving at an extremely rapid pace, but still face limitations in areas such as personalization and search efficiency. LLMs cannot build and provide information in real time, and they do not offer personalized services. The introduction of Retrieval-Augmented Generation (RAG) has largely mitigated hallucination issues, but LLMs still lack long-term memory. When the same question is asked at different times, the interaction must begin from scratch because of structural constraints that prevent AI from providing customized services for individual users.
Vector database search is seen as a breakthrough to resolve these issues. A vector database (vector DB) stores data such as images and text in a numerical representation that computers can precisely distinguish. The current scalar database (scalar DB) search method differentiates data using specific values such as data or strings (scalars), and when it receives a query and generates a response, it retrieves results based on keywords or conditions, which is inefficient and causes bottlenecks. In contrast, a vector DB operates by finding semantically similar items, which significantly improves search efficiency and enhances the completeness and performance of responses.
Microsoft has added vector search capabilities to non-relational databases, which handle unstructured data, on its Azure cloud platform. Google has also added a dedicated engine capable of processing billions of vectors to Vertex AI, and AWS is integrating vector DB search functions into existing scalar DBs through the AWS OpenSearch Service, which supports similarity search algorithms.
Jung Moo-kyoung, CEO of Dnotitia / Source=ITDongA
The challenge is that existing AI hardware is not structurally suited for leveraging vector DBs. In simple terms, similarity search for vector DBs is being executed using legacy scalar methods, which lowers power and computing efficiency. For now, the approach is effectively to throw large amounts of hardware at the problem to make vector DBs usable. Dnotitia is building dedicated AI accelerators and a cloud infrastructure to address this. Dnotitia describes itself as an integrated long-term-memory AI and semiconductor solutions company, and is developing VDPU, a semiconductor dedicated to vector DB processing, along with Seahorse Cloud, a cloud service also dedicated to vector DB processing.
Dnotitia to launch VDPU this year and complete its AI storage service
On 3 March, Dnotitia held a press conference and officially announced its “AI storage” strategy for implementing long-term-memory AI. CEO Jung Moo-kyoung said, “As of 2026, technologies for large language models such as GPT and Claude are converging upward in quality, and in the end, service differentiation will depend on how data is personalized and how far we can improve the quality of different data types. Through vector DBs, LLMs can provide real-time information, personalized services, verifiable grounding, and long-term memory.”
He continued, “Dnotitia is building its vector DB market strategy on three memory tiers: external memory for retrieval-augmented generation, agentic memory for long-term memory, and short-term memory corresponding to the KV cache. Even now, 85% of data becomes dark data that is never used after creation, but if this is converted into vector DBs and examined through similarity search by AI, AI performance and efficiency will be maximized. Dnotitia will pursue ‘AI storage’ as its core strategy for processing and storing this data.”
Dnotitia is also focusing on the fact that LLMs do not technically support long-term-memory modules, and that the performance efficiency of short-term memory is structurally limited. Jung said, “The architecture of LLMs does not allow real-time learning, so they do not store generated data as long-term memory. To perform the same task, a session must be opened and everything must be explained again from the beginning.”
CEO Jung introducing Dnotitia’s Seahorse Cloud and VDPU-related technologies / Source=ITDongA
Types of long-term memory are categorized into: ▲ episodic memory for recording past events and experiences ▲ semantic memory for handling knowledge such as general facts or concepts ▲ procedural memory for handling how to use tools or perform tasks. To integrate these, AI would need to be activated routinely, but as storage space grows too large, the only viable approach is to treat it as a storage device rather than as memory. Dnotitia aims to address the storage layer with its AI-based Seahorse Cloud.
The final tier, short-term memory, refers to the KV cache that holds real-time conversation logs. The real-time conversation history of an LLM is temporarily uploaded into the memory of the AI accelerator, and the longer the context, the more memory is required. Increasing accelerator capacity is one solution, but costs soar. Recently, Nvidia introduced ICMS (Inference Context Memory Storage), a technology that connects GPUs and storage at high speed to store KV caches, in order to solve this problem. Dnotitia’s AI storage is being designed to be compatible with ICMS, and is in the process of integrating with Nvidia’s BlueField Data Processing Unit and SmartNIC (network interface card).
The reason for dividing memory into three tiers is to deploy the technological assets invested in AI storage as broadly and effectively as possible. Jung said, “Within five years, the access frequency of AI data is expected to increase by up to 5,000 times, and the AI storage market could grow to as much as USD 28.3 billion (about KRW 4.18 trillion). The domestic SSD market is sizable, but there are few solutions built on it, with Dell EMC, NetApp, IBM, and Pure Storage currently accounting for a significant share. Dnotitia will also target this market.”
AI token consumption up 80-fold… Efficiency now as important as securing infrastructure
CDO Noh Hong-chan explains the pipeline configuration of Seahorse Cloud and AI storage / Source=ITDongA
Dnotitia’s AI storage aims to vertically integrate all layers from software based on Seahorse Cloud and hardware based on VDPU to the entire process from data preprocessing to vector DB handling. Chief Data Officer (CDO) Noh Hong-chan said, “With the spread of AI agents such as OpenClo and Claude Co-Work, the software market faces an unprecedented crisis. SSD and memory prices have soared more than fivefold compared to last year, and token consumption has increased more than 80-fold. Conventional chatbots consume around 1K tokens, but general-purpose AI agents repeatedly store, read, modify, and respond, consuming more than 80,000 tokens.”
He continued, “The problem is that the existing data processing method is inefficient. In the conventional workflow, data is loaded from a file server, text is extracted using a document parser, it is then recognized by vision and language models, the document is split by a chunking engine, converted to vectors by an embedding server, and finally processed by a vector DB. Dnotitia will integrate all these steps at the software level and, in our second-stage products, apply VDPU to deliver cost-efficient solutions.”
The strategy is to consolidate what used to be up to six separate data processing pipelines into a single AI storage unit for unified management / Source=ITDongA
In particular, Dnotitia also intends to resolve the issue of duplicate data storage. In conventional AI processing pipelines, scalar DBs and vector DBs are operated separately. When processing vector DBs, files are fetched over the network from distributed storage, processed, and then handled again in storage. Dnotitia proposes “vector-native storage,” in which data is stored on a single storage system and vector DB processing is performed in vector form. In April last year, Dnotitia launched a managed vector DB service and, based on this core technology, began offering Seahorse Cloud 1.0. Starting this year, it will integrate the preprocessing stage into storage and release a version that supports vector DB acceleration via VDPU.
Regarding business performance, CDO Noh said, “It is difficult to confirm details publicly, but proofs of concept (PoCs) with overseas companies are proceeding step by step, and there are concrete business opportunities in Korea as well. Although we cannot disclose specifics about domestic data center business, progress is being made.”
VDPU, the core of AI storage, to enter mass production this year
CTO Yang Se-hyun explains the technical overview of the first-generation VDPU / Source=ITDongA
The VDPU (Vector Data Processing Unit), which Dnotitia is independently developing, is a dedicated processing unit designed to resolve the vector DB pipeline at the storage-device level. CTO Yang Se-hyun explained, “Data for external knowledge or long-term memory is mostly unstructured, and such data is exploding. The industry is approaching this by letting AI process this data. Given the vast scale of data, it is difficult to distinguish it using only file names or keyword searches; semantic search is needed. The cost of storing AI context is also rising, and demand for KV caches that temporarily store conversation content is increasing sharply. If all of this is processed only on GPUs, GPU costs will surge.”
The core idea is for VDPU to handle vector DB processing tasks that CPUs or GPUs process inefficiently. Its key functions include vector search acceleration, KV cache compression, inference context management, and a VDPU serial data transmission interface. VDPU completed tape-out last year using TSMC’s 12 nm process and will enter full-scale mass production this year. It will be built in the form of a PCIe card to ensure device compatibility and will adopt LPDDR5X to deliver a low-power, high-capacity environment.
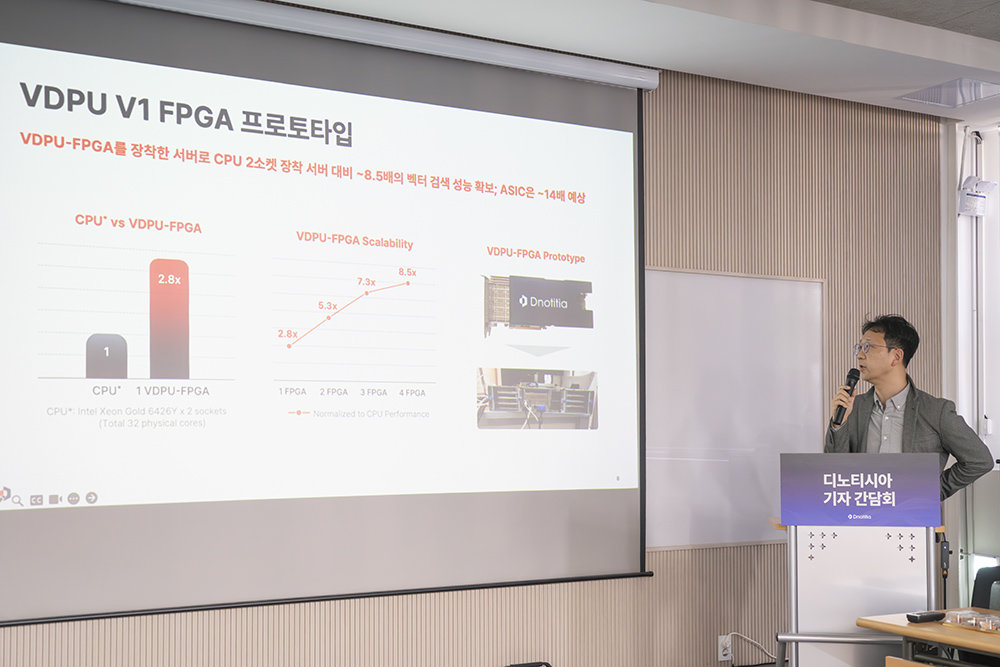
A system configured with a first-generation VDPU on FPGA delivered 2.8 times higher performance than two CPUs / Source=ITDongA
The company configured the first-generation chip on an FPGA (field-programmable gate array) and tested part of the vector search functions. Comparing the vector DB search performance of a server equipped with two Intel Xeon Gold 6426Y CPUs and a system with one VDPU-FPGA, the latter showed about 2.8 times higher performance. With two VDPUs, performance rose 5.3 times; with three, 7.3 times; and with four, 8.5 times. Even taking into account the provisional nature of an FPGA-based configuration, the efficiency gap has been verified, and Yang explained that if the device is implemented as an ASIC (application-specific integrated circuit), vector DB search performance could improve by up to 14 times.
Series A to close in March, value to be demonstrated through this year’s results
Dnotitia plans to expand its ecosystem not only through AI storage but also by providing VDPU intellectual property / Source=ITDongA
Dnotitia’s push into vector DBs is progressing smoothly. In September last year, the company began commercializing the intellectual property (IP) corresponding to VDPU design diagrams. While selling the vector DB system itself is important, allowing hyperscalers and other operators that handle vector DBs to directly design and use VDPUs can expand the ecosystem. Yang said, “System-on-chip (SoC) manufacturers are showing interest in Dnotitia’s IP, and there are many memory and storage controller companies as well.”
Although storage prices are rising, this is not expected to have an immediate impact on Dnotitia’s business. Jung commented, “We have not yet decided which manufacturer’s storage devices will be used in AI storage, and we are exploring various options. As SSD and memory prices both climb, global companies are continuously seeking ways to use devices more efficiently, and leveraging AI storage can further boost infrastructure performance. In the long run, related demand will only increase.”
CEO Jung stated that the company plans to demonstrate tangible results and value this year through commercialization and global market expansion / Source=ITDongA
Dnotitia plans to complete its Series A funding round in March. Based on this, the company will establish the foundation for AI storage using Seahorse Cloud this year, begin mass production of VDPUs in the second half, and target AI companies and hyperscale cloud operators facing storage and memory shortages and demanding efficient AI data processing. As Dnotitia is the first in the world to introduce a semiconductor in the form of VDPU, it is difficult to easily gauge market potential, but the company has secured resilience by diversifying into LLM- and cloud-related businesses, and its roadmap appears achievable. The remaining question is whether it can successfully ramp up mass production and how many companies will adopt its AI storage solutions.
Reporter Nam Si-hyun, ITDongA (sh@itdonga.com)
ⓒ dongA.com. All rights reserved. Reproduction, redistribution, or use for AI training prohibited.
Popular News